Gemini VS GPT-4V:Who is better?Full comparison in various domains


Recently Tencent YouTu Lab released a visual model review paper "A Challenger to GPT-4V? Early Explorations of Gemini in Visual Expertise" about GPT4V and Google's Gemini pro.
I extracted part of the content and summarized and translated it for your reference and reading.
The boom in multimodal large language models (MLLMs), such as OpenAI's GPT-4V(ision), has been a notable trend in academia and industry.
These models have endowed Large Language Models (LLMs) with power in visual understanding, enabling them to handle diverse multimodal tasks.
Recently, Google introduced its latest and greatest multimodal model, Gemini, which was designed from the ground up to handle multimodal problems.
Considering its extraordinary inference capabilities, is Gemini expected to challenge GPT-4V's leadership in multimodal learning?
This thesis preliminarily explores Gemini Pro's capabilities in visual understanding, which includes basic perception, advanced cognition, complex visual tasks, and various expert-level capabilities.
Gemini Pro is compared to the industry-leading GPT-4V to assess its limits and to the latest open-source MLLM Sphinx to reveal differences between manual tasks and closed systems.
Qualitative sample analysis reveals that while GPT-4V and Gemini differ in their answering styles and preferences, they are comparable in terms of visual reasoning ability, while Sphinx is slightly less successful in terms of domain generalization.
Specifically, GPT-4V tends to provide detailed explanations and intermediate steps, while Gemini prefers to give direct and concise answers.
Gemini also performs very well in multimodal understanding in the popular MME benchmark designed for MLLM, showing its potential to be a strong competitor to GPT-4V.
Early research on Gemini has also pointed out common problems in visual understanding, logical reasoning, and cue robustness in MLLMs, showing that there is still quite a way to go before true artificial general intelligence is realized.
It is hoped that this report will provide new ideas for future MLLM research and applications.
Translated with DeepL.com (free version)
The link to the project with a comprehensive collection of MLLM advances is: https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
Introduction.
Driven by Big Data and powerful computational capabilities, the field of Large Language Models (LLMs) has realized unprecedented excitement and progress, and its generality across a wide range of domains is particularly compelling. Building on this foundation, multimodal large language models (MLLMs) are becoming the centerpiece of a new generation of research.
The goal of these models is to combine LLMs with additional sensory input.
Based on new modal data, MLLMs are an important step on the path towards generalized AI. Of particular note, OpenAI's GPT-4V(ision) is considered to be the most powerful MLLM to date, surpassing a range of LLaMA-based models such as LLaMA-Adapter, LLaVA and MiniGPT-4.
However, Google's recently released Gemini has emerged as a strong challenger to GPT-4V, demonstrating significant multimodal capabilities in several benchmarks.
Given that the full potential of Gemini has yet to be fully explored, in this paper, Gemini's multimodal capabilities are revealed by comparing it to the best current MLLM GPT-4V.
For a comprehensive evaluation, qualitative samples covering different multimodal understanding domains were carefully collected. Two existing representative MLLMs were chosen as benchmarks:
One is the GPT-4V, which represents the current highest standard in the field, to evaluate the upper limit of Gemini;
The second is the latest LLaMA-based MLLM Sphinx, which explores the performance gap between open-source models and closed-source systems.
Specifically, the qualitative sample is divided into the following four visual domains:
- Basic Perception: This dimension focuses on the ability of MLLMs to perceive and understand visual concepts at a basic level without complex reasoning. It consists of three key dimensions: object-centered perception, scene-level perception, and knowledge-based perception. Object-centered perception evaluates the model's ability to recognize and interpret individual object features in the visual context, such as spatial relationship recognition, object counting, and disparity discovery. Scene-level perception assesses overall scene understanding from a global perspective, as reflected in image and video descriptions. Finally, knowledge-based perception demonstrates the model's ability to accumulate and apply specific knowledge in different domains, including general knowledge, scientific knowledge, cultural practices, and world memory.
- Advanced cognition: This part of the sample requires MLLMs to process more complex visual information and perform multimodal reasoning to solve problems. Tasks involved include rich text and abstract visual reasoning, scientific problem solving, emotion understanding, and game play. Rich text tasks involve OCR performance for textual content, table and chart reasoning, and code generation based on different visual inputs. Abstract Visual Reasoning is a non-verbal test that assesses general intelligence and abstract reasoning, such as the Wechsler Adult Intelligence Scale and the Raven Progressive Matrices. Scientific problem solving (e.g., math and physics) becomes a key measure of MLLMs' understanding of quantitative and logical knowledge, involving complex multi-step and chain-of-thought reasoning. Emotional comprehension focuses on detecting emotional information in visual contexts, and game play assesses strategic thinking and rule-following abilities in games, such as Sudoku.
- Challenging Visual Tasks: This section aims to evaluate the performance of MLLMs on challenging visual tasks that go beyond conventional visual quizzing, such as object detection, finger expression comprehension, phrase localization, and video temporal reasoning. These tasks test the in-depth visual perception and comprehension abilities of MLLMs. the performance of MLLMs reflects their potential as versatile visual generalists.
- Expertise: This dimension focuses on evaluating the model's skills in multiple specialized domains. These domains include medical imaging, defect detection, stock prediction, autonomous driving, and surveillance security. In these domains, models are tested on how they can apply their learned knowledge and cognitive skills to specialized settings, such as diagnosing diseases or predicting stock market trends using medical imaging. This point demonstrates the ability of MLLMs to generalize to broader domains.
In addition to the qualitative sample, we also report quantitative results from Gemini on the popular MME benchmark test in Section 6. This test comprehensively evaluates the performance of MLLMs on 14 subtasks from both perceptual and cognitive perspectives.
I. Evaluation Kits
1.1 Hinting Techniques
GPT-4V has been shown to support a variety of hinting techniques, ranging from simple instruction following to example less learning in context. This has inspired the design of the following prompting techniques.
Simple instructions: This approach directly expresses the user's intent, e.g., "Describe this picture" or "Who is the person in this poster?" . Existing MLLMs are usually able to follow such instructions, allowing them to accomplish most tasks effectively.
Visual referencing cues: In many cases, a simple visual marker can be more effective in conveying a user's interest in a particular spatial area than complex and lengthy text. Try, for example, using a physical object (e.g., a finger or pen) as a cue to guide the model in understanding the referenced object. Using real objects as cues is more practical in real-time interaction scenarios than visual markers.
Chain of Thought (CoT) prompts: For problems involving complex logical reasoning, use CoT techniques to guide the model through a series of logical thinking processes to give a final answer.
Learning with fewer examples in context: In cases where simple textual instructions cannot fully demonstrate the task, learning with fewer examples in context is used to provide better hints. By providing a few examples at the time of reasoning, the model is able to infer the intent from these examples to better generate the desired output.
1.2 Sample Collection
Avoid sample leakage: make sure that the qualitative images and text collected are unseen by the model to avoid responses that only reflect the memory of the training data.
All text in the query is newly constructed. Image sources included hand-drawn images, offline photographs, Internet images, and some existing datasets. For Internet images, images with timestamps after November 2023 were specifically collected.
Diversity of difficulty: Samples of different difficulty levels were collected for each task, ranging from basic perception and cognition to more challenging visual and expert tasks.
In this way, we were able to not only demonstrate the potential of the MLLMs to accomplish these tasks, but also explore the boundaries of their capabilities through some obvious error patterns.
II. Measurement of Basic Perception
In the context of multimodal macromodeling, base perception refers to the ability of a model to process and interpret primarily visual sensory data to form a coherent understanding of the environment it perceives.
The level of perceptual ability directly affects the model's performance in higher-level tasks, and it determines the accuracy and efficiency with which the model acquires and processes raw visual input.
In Section 3.1, object-centered perceptual tasks such as spatial relationship recognition, object counting, and finding differences will be explored in depth. In Section 3.2, the model's ability to interpret complete scenarios from different domains will be examined.Section 3.3 will explore the model's ability to make sense of visual information through the application of knowledge, which includes aspects of common sense, specialized knowledge, multicultural habits, and world memory.
2.1 Object-centered perception
Spatial relationship recognition. We examine the ability of models to understand spatial relationships and find that they have difficulty distinguishing left from right. For example, as shown in Figure 1, the person to the left of Jordan is James, but both Gemini and GPT4-V responses misidentify Kobe, while Sphinx's response is Jordan. A small amount of shot learning in context is used to help the model understand the concept of "left side". As shown in Figure 2, the model is given two example images of the "left side". However, only GPT-4V successfully learned this concept, and Gemini and Sphinx still cannot distinguish between left and right.

Figure 1: Results of spatial relationship identification. All three models failed to give the correct answer. Wrong answers are marked in red in the figure and deficiencies in accomplishing the task are marked in yellow.

Figure 2: Results of spatial relationship identification. After providing two examples, GPT-4V successfully and accurately recognized the spatial relationship, but the other two models still answered incorrectly. The green color in the figure marks the correct answer and the red color marks the wrong answer.
Object Counting. The ability of the model to count objects is demonstrated. For simple samples, the open-source model Sphinx performs similarly to the two closed-source models, which is particularly evident in the first three cases. However, as shown in the fourth case, all three models are prone to errors when the image contains too many visual elements.
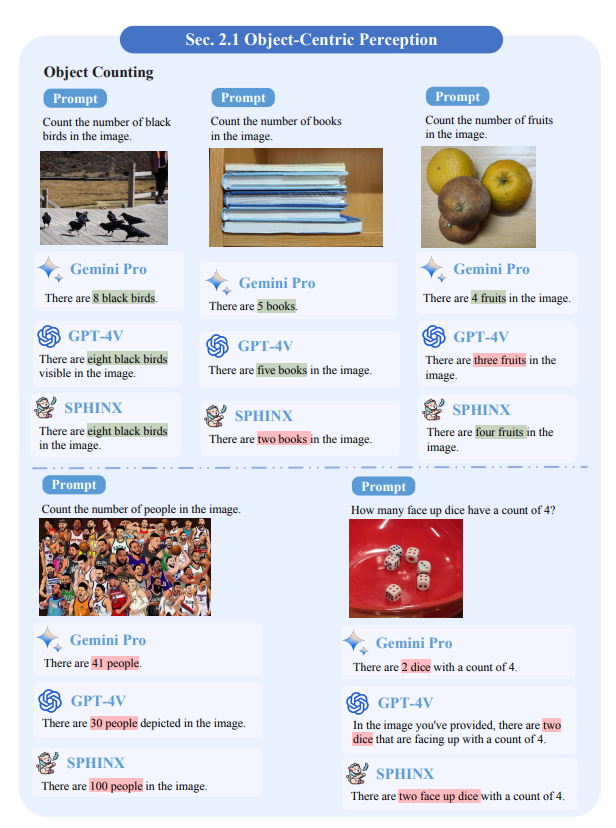
Figure 3: Results of object counting. The green color in the figure marks the correct answer and the red color marks the wrong answer.
Difference Discovery. In Figure 4, the ability of the models to detect differences in cartoon images, sketches, and real photographs is demonstrated. It is noted that all models are able to detect small differences between images, although their performance is not always stable. It was also found that Gemini and GPT-4V were easily misled by intentionally provided false cues. For example, in Figure 5, there are actually only three differences, but when the models were asked to identify five differences, both models incorrectly indicated five different points.

Figure 4: Results of discrepancy finding. The green color in the figure marks the correct answers, the red color marks the incorrect answers, and the yellow color marks the deficiencies in completing the task.

Figure 5: Difference finding results. There are actually only three discrepancies in these two images, but we asked the model to find five. both Gemini and GPT-4V attempted to respond to our request by providing five discrepancies, but neither performed as well as they could have. Wrong answers are marked in red in the graphs.
Optical illusion recognition. As shown in Figure 6, we investigated whether these models can understand optical illusions as well as humans. For example, on the left side of the figure, the brightness of the two pears is actually the same, but the black and white stripes create the illusion that the pear on the right side looks brighter. gemini correctly recognizes that the two are the same brightness, whereas GPT-4V and Sphinx are confused by the optical illusion and think that the pear on the right side is brighter. In the right part of the figure, GPT-4V recognizes that the angles of the trunk and branches are similar to those of a human body and arm, again demonstrating its human-like visual understanding of optical illusions.

Figure 6: Results of visual illusion recognition.GPT-4V shows human-like cognition in visual illusion understanding. The green color in the figure marks the correct answer and the red color marks the wrong answer.
2.2 Scene-level perception
Image scene understanding: The text query "describe this image in detail" prompts the model to recognize all visual elements in the image in as much detail as possible. Figure 8-10 shows that all three models are able to describe the key visual elements in the scene. However, in this comparison, GPT-4V performs better, especially in complex and chaotic environments, as shown in Fig. 8, where GPT-4V provides more detailed descriptions and fewer hallucinations.

Figure 8: Results of image-scene comprehension. the GPT-4V provides more detailed descriptions and fewer hallucinations occur. The green color in the figure marks the correct answer and the red color marks the wrong answer.

Figure 9: Scene comprehension results for the image. Possibly influenced by the Japanese architectural style of the image, Gemini inserted a Japanese sentence into its English response. Green color highlights the correct answer. Yellow highlights incompetence in performing the task.

Figure 10: Results of image scene understanding. Only GPT-4V correctly recognized that the two images show different views of the same scene. The green color in the figure marks the correct answer.
Video Scene Understanding: The model's ability to understand the video scene is examined. As shown in Figure 11, three temporally distinct frames were extracted from the video and fed into the model in conjunction with the textual query "Please describe the scene based on these temporal images". It is observed that Gemini is able to fuse the information from the different frames into a coherent scene description. In particular, the first frame shows two round tables and a potted plant, while the second frame shows one round table and three potted plants. It is noteworthy that Gemini successfully fused the information from these two frames to accurately describe the scene as containing two round tables and three potted plants. In contrast, GPT-4V describes the image content frame by frame, while Sphinx's description fails to fully understand the image sequence.

Figure 11: Results of video scene comprehension.Gemini successfully merged the information from the first two frames to accurately describe the scene as containing two round tables and three potted plants. The green color in the figure marks the correct answer.
2.3 Knowledge-based perception
Common Sense: Figures 12-15 demonstrate the ability of the three models to apply common sense to understand the visual information in an image. As can be seen, the open source model Sphinx performs comparably to Gemini and GPT-4V in applying social norms, as shown in Figure 12-13. However, it performs slightly less well in applying the laws of physics. For example, Gemini and GPT-4V are able to accurately select heavy clothing for cold Antarctic weather, as shown in Figure 14. Interestingly, although Sphinx recognizes the need for heavy clothing in cold weather, it incorrectly identifies the T-shirt as suitable for cold protection.

Figure 12: Results of common sense perception. The green color in the figure marks the correct answer

Figure 13: Results of common sense perception. The green color of the graph marks the correct answer and the yellow color marks the deficiency in completing the task

Figure 14: Results of common sense perception. Although Sphinx understands the need for thick clothing in cold weather, it incorrectly categorizes T-shirts as suitable for cold weather protection. The green color in the figure marks the correct answer and the red color marks the incorrect answer.

Figure 15: Common sense perception results. both Gemini and GPT-4V recognized that the second image showed a flame disguised with lights, but the difference was that Gemini inferred that the object in the image could be touched, and GPT-4V additionally warned of the risk of electric shock. The green color in the image marks the correct answer, the red color marks the incorrect answer, and the yellow color marks deficiencies in completing the task.
Expertise: In Figures 16-19, we examine the ability of the models to apply their knowledge in the areas of physics, chemistry, and history. It is observed that both Gemini and GPT-4V have expertise related to these cases.Sphinx performs a little less well, but is able to provide correct answers in some cases.
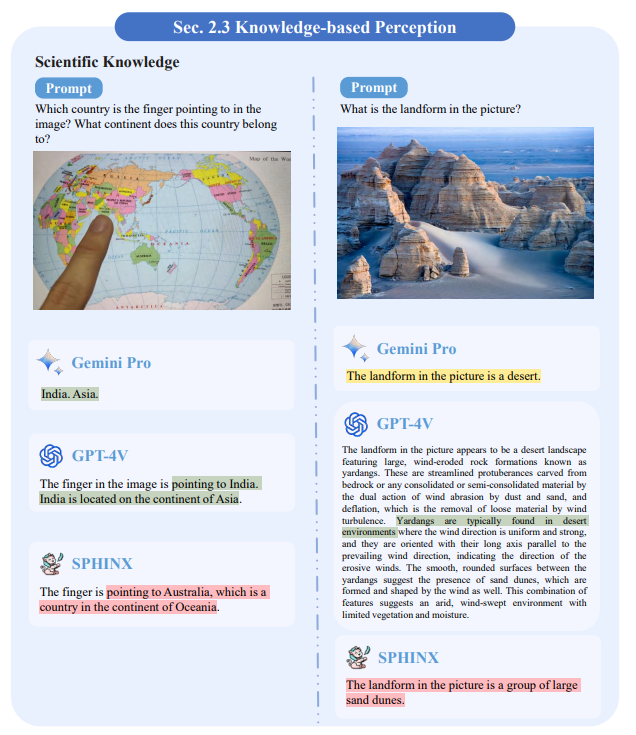
Figure 16: Scientific Knowledge Perception
Figure 16: Results of scientific knowledge perception. The green color in the figure marks the correct answers, the red color marks the wrong answers, and the yellow color marks the shortcomings in completing the task.

Figure 17: Results of perceived scientific knowledge. The green color of the graph marks the correct answer, the red color marks the wrong answer, and the yellow color marks the deficiency in completing the task.

Figure 18: Results of Perceived Scientific Knowledge. The green color of the graph marks the correct answer and the yellow color marks the shortcomings in completing the task.

Figure 19: Results of the perception of historical knowledge. The green color in the graph marks the correct answers and the red color marks the incorrect answers.
Multicultural practices: we examined the model's ability to understand multicultural elements. We showed images with distinct local ethnic and cultural characteristics and prompted the models to provide descriptions. Figures 20-22 show that all three models were able to understand the ethnic and cultural elements in the images.

Figure 20: Results of multicultural knowledge perception. The green color in the figure marks the correct answers and the red color marks the incorrect answers.

Figure 21: Results of multicultural knowledge perception. The green color in the figure marks the correct answer.

Figure 22: Results of Multicultural Knowledge Perception.
Figure 22: Results of multicultural knowledge perception. The green color in the figure marks the correct answer.
Memory of the World: We investigated the model's ability to recognize globally known celebrities, landmarks, logos, movies, foods, plants, animals, etc. As shown in Figure 23-38, we observed that the model usually recognizes them correctly. However, the model's descriptions were not accurate when the images reflected recently updated information, as shown in Figure 24. In addition, GPT-4V sometimes chose not to respond when asked for information related to real people, as shown in Figure 29.

Figure 23: Results of celebrity identification and description.Sphinx incorrectly assumes that Dr. Strange in his Iron Man armor is Iron Man himself. The green color in the figure marks the correct answer and the red color marks the incorrect answer.

Figure 24: Results of celebrity recognition and description. Gemini's descriptions are often inaccurate when the images display recently updated information. For privacy reasons, GPT-4V avoids answering questions related to the identification of celebrities. The green color in the figure marks the correct answer, the red color marks the incorrect answer, and the yellow color marks the deficiency in completing the task.
Figure 29: Results of movie recognition and description. The green color in the figure marks the correct answer and the red color marks the incorrect answer.

III. Advanced Perception
On top of basic perception, we further evaluated the more advanced cognitive abilities of Gemini, GPT-4V, and Sphinx.The cognitive tasks of the MLLMs require not only understanding multimodal concepts in a visual context, but also in-depth reasoning, problem solving, and decision making.
In Section 3.1, the first focus is on the model's ability to process rich textual visual content, including table and diagram reasoning and visual code generation. In Section 3.3, the logical and quantitative comprehension capabilities of MLLMs are explored in depth to solve challenging scientific problems that require pre-trained knowledge, such as math and physics. In Section 3.2, it is examined how the model reasons about abstract visual stimuli, the Raven's Progressive Matrices, and abstract visual information in the Wechsler Adult Intelligence Scale. In Section 3.4, the model's understanding of emotion is explored through different scenarios such as facial expression analysis, image emotion analysis, and emotion conditional output. Finally, in Section 3.5, the decision-making ability of the MLLMs is evaluated in a variety of mind games including Sudoku and Go.
3.1 Text-Rich Visual Reasoning
Tabular and Diagrammatic Reasoning: in Figures 39-40, we show two samples of flowchart comprehension by the three models. gemini is able to accurately summarize the main ideas of a flowchart in concise sentences. gpt-4v tends to provide more detailed descriptions of the logical flow of a diagram, but sometimes makes mistakes.

Figure 39: Shows the results of tabular and diagrammatic reasoning. Correct answers are marked in green and incorrect answers are marked in red.

Figure 40: Shows the results of reasoning with tables and diagrams. Correct answers are highlighted in green and incorrect answers are highlighted in red.
In contrast, Sphinx fails to extract their meanings due to the lack of relevant pre-training data. In Figures 41-43, we evaluate the quiz performance of six different charts and tables. Similar to previous demonstrations, GPT-4V provides more inference details than Gemini. However, all three models struggle to provide precise answers, limited primarily by suboptimal OCR accuracy. Furthermore, as shown in the last sample, Gemini and GPT-4V were able to understand hand-drawn visual cues, although Gemini provided incorrect final answers, suggesting that they have the ability to generalize to visual input.

Figure 41: Shows the results of tabular and graphical reasoning. Correct answers are highlighted in green and incorrect answers are highlighted in red.

Figure 43: Shows the results in tabular and graphical reasoning. The Gemini on the left gives a contradictory answer. GPT-4V, on the other hand, not only answered the question accurately, but also pointed out the miscalculation in the bill on the right. The correct answer is highlighted in green, the wrong answer in red.
Visual code generation: Converting structured visual content into corresponding code is an important skill for MLLMs. In Figures 44-45, the three models were asked to generate LaTeX code for various mathematical formulas and rendered for comparison. Overall, Gemini and GPT-4V outperform Sphinx, but still misrecognize some small characters or symbols.

Figure 44: Visual Code Generation Results

Figure 45: Visual Code Generation Results
3.2 Abstract Visual Reasoning
Abstract Visual: This task evaluates the visual abstraction capabilities of object composition. As shown in Figures 48-49, GPT-4V performs best in terms of abstraction and provides a detailed description of how objects are composed of shapes. In contrast, Gemini was only partially able to recognize simple abstract patterns such as "boat" and "house", which Sphinx could not understand.

Figure 48: Abstract visual stimulus results, green for correct answers, red for incorrect answers and yellow for poor task performance.
3.3 Scientific Problem Solving
Math Problems: Unlike common visual quizzes, solving math problems involves both OCR capabilities from the visual input and quantitative processing accuracy in subsequent inference steps. In Figures 54-59, we show some math problems involving arithmetic, algebra, geometry, and integral calculus. The samples show that Gemini and GPT-4V can handle simple arithmetic and algebraic problems well. For more difficult trigonometry and integral calculus problems, they also demonstrate good reasoning performance with the help of external tools. However, they are not very good at recognizing specific visual content in images, such as numbers, symbols and their correspondences. In addition, we observed that using the CoT technique, i.e., "Please think step-by-step", Sphinx can correct previous incorrect answers, demonstrating the importance of CoT hints for open-source MLLMs.

Figure 54: Math problem solving results, with green indicating correct answers, red indicating incorrect answers, and yellow indicating poor task performance.
Physics problems: These problems further require MLLMs to understand specialized vocabulary and concepts in physics. In Figures 60-62, we show the results of three MLLMs solving the dynamics, kinematics, and circuitry problems. As shown, Gemini and GPT-4V demonstrate good reasoning performance for physics problems and make good use of pre-trained expertise as a reference. However, their performance may be limited by mathematical computations, such as the range of integrals, and the accuracy of physics equations, such as the energy conservation equation. Due to the scarcity of training data for physics problems, open source Sphinx clearly lacks the ability to solve such scientific problems with graphs.

Figure 61: Physics problem solving results, with correct answers in green and incorrect answers in red.
3.4 Emotional Understanding
Facial Expression Analysis: In Figures 63-64, we evaluate the ability of the different models to understand facial expressions. As shown, all three MLLMs perform well in this task. Among them, GPT-4V provides a more rigorous analysis with dialectical thinking, e.g., the two possibilities of the first expression, while Gemini can directly give accurate answers with concise information. In addition, both GPT-4V and Sphinx capture the truncated textual content on the plate in the third image and incorporate this information into their reasoning. This result demonstrates their comprehensive visual comprehension capabilities.

Figure 63: Facial expression analysis results, with green indicating correct answers, red indicating incorrect answers, and yellow indicating poor task performance.
Image Sentiment Analysis: The image sentiment analysis task is quite challenging because facial expressions are not directly displayed in the images. This requires a large language model that can reveal the hidden emotions in the images. In Figures 65-69, we have selected various samples of natural landscapes and man-made buildings. All three models are able to accurately describe the landscapes first and then speculate the possible emotions in them. In this process, GPT-4V usually remains neutral and emphasizes that emotions are subjective, while providing a more comprehensive analysis. Gemini, on the other hand, tends to express sentiment preferences directly, which is in line with popular opinion. On the other hand, Sphinx's performance in sentiment parsing is comparable to the other two models.

Figure 68: Image sentiment analysis results, green indicates correct answers and yellow indicates poor task performance.
In terms of emotion-conditioned outputs, unlike predicting the mood of an image, this feature allows the biglanguage model to describe a visual scene based on a specific mood, such as "romantic or scary way". In Figs. 70-71, although both Gemini and GPT-4V correctly incorporate the appropriate emotions into the generated text, they sometimes have problems with hallucinations, such as describing things that do not exist, e.g., "bicycle" and "shadows" in the first image, and "shadows" in the second image. "in the first image, and "sound" in the second image. This may be due to their strong associative power. In contrast, Sphinx does not have this problem, demonstrating the advantages of large language models modeled on humans.

Figure 70: Sentiment conditioned output, yellow color indicates poor task performance.
Section 4 Visual Tasks
In this section, the goal is to evaluate the performance of MLLMs on a variety of challenging visual tasks that are beyond the scope of standard visual quizzes. These tasks require MLLMs to have deep visual perception and comprehension skills. Evaluating their performance in these domains will provide insights into MLLMs as versatile generalists.
In Section 4.1, the discussion will focus on the ability of the models to perform vision-related tasks at the image level, including target detection, finger representation understanding, phrase localization, and face detection and recognition. In Section 4.2, time-series based vision tasks such as video action recognition, target tracking, and visual story generation will be explored.
4.1 Image-level vision tasks
Target Detection: explores the ability of the model to perform a target detection task that requires the model to provide a bounding box for each car and person in the image. As shown in Figure 77, the bounding boxes provided by Gemini are usually imprecise, while GPT-4V avoids providing coordinates directly and instead tries to use external tools. Only Sphinx provides a relatively reliable answer, but its performance is significantly lacking compared to traditional target detectors.

Figure 77: Target detection results. bounding boxes for Gemini are often not accurate enough, while GPT-4V usually avoids providing coordinates directly, preferring to use external tools. Although Sphinx provides more reliable answers compared to other models, it still falls far short of the performance of standard target detectors. Green color indicates correct answers and red color indicates incorrect answers.
Expression comprehension: Here, we evaluate the ability of the model to provide bounding boxes referring to objects. We ask the model to generate standardized bounding boxes. As shown in Figures 78-79, both Gemini and GPT-4V are able to recognize the approximate location of the referring object, but have difficulty providing precise coordinates and box sizes. However, Sphinx demonstrated the ability to provide the exact location and size of the referring object.

Figure 78: Results of referring object comprehension. Only Sphinx provided satisfactory results. Green color indicates correct answers and red color indicates incorrect answers.
Phrase localization: Here, the ability of the model to phrase localize is evaluated. Its required that the model provides bounding boxes for all nouns in the description. As shown in Figure 80, all three models failed to perform this task satisfactorily.

Figure 80: Phrase localization results. All three models failed to provide correct results. two of the bounding boxes provided by Gemini were out of range and the remaining one was wrong. sphinx failed to understand the instructions and provided only one bounding box. Of the bounding boxes provided by GPT-4V, only Zebra's was nearly accurate. Green indicates a correct answer, red indicates an incorrect answer, and yellow indicates a lack of ability to perform the task.
Face detection and recognition: an important task in computer vision. The model is prompted by the textual query "Detect all faces in an image and state who they are?" to prompt the model. As shown in Figure 81, without explicit instructions to provide bounding boxes, Gemini accurately recognizes the arrangement of all faces in the image and accurately identifies the corresponding name of each face. Meanwhile, GPT-4V issued a privacy statement and dodged the request.Sphinx's response almost provided the correct bounding box, but failed to recognize the faces.

Figure 81: Face Detection and Recognition Results. the Gemini recognized the name of each face in the image in left-to-right order. In contrast, GPT-4V issued a statement about privacy and chose not to fulfill the request. On the other hand, Sphinx generated a nearly accurate bounding box, but failed to identify the faces. Green color indicates a correct answer, red color indicates an incorrect answer, and yellow color indicates a lack of ability to perform the task.
4.2 Time-Level Vision Tasks
Target tracking: here, the model's ability to perform target tracking will be explored. As shown in Figure 82, although both Gemini and GPT-4V were able to outline the details of the target to be tracked, they then provided incorrect bounding boxes in the next two frames.The Sphinx's responses indicate that it failed to understand the intent of our instructions.

Figure 82: Target tracking results. Although Gemini and GPT-4V perform well in describing the target to be tracked in detail, they both provide incorrect bounding boxes in the next two frames.
Video Action Recognition: figures 83-85 demonstrate the model's ability to recognize the actions of people in a video. Five representative frames were extracted from the video segment and fed into the model. As shown in Figure 83, both Gemini and GPT-4V were able to recognize the actions in the images and provide detailed descriptions. Although Sphinx's response was correct, it lacked a detailed description.

Fig. 83: Video action recognition results. Green color indicates a correct response and red color indicates an incorrect response.
Visual Story Generation: this task requires MLLMs to fully understand the information in the images and to organize this information rationally in the generated story. As shown in Figure 86, Gemini provided a coherent story that coincided with the first two cartoons.GPT-4V provided an accurate description of each illustration; however, it failed to weave them into a coherent story as required by the task.Sphinx's story deviated even further from the context of the cartoon, containing only certain elements from the illustrations. In addition, its story logic seems somewhat unexplainable.

Figure 86: Visual Story Generation Results
Figure 86: Visual story generation results.Gemini provides a coherent story that matches the first two comics.GPT-4V provides precise descriptions for each comic, but does not provide a storyline.The correlation between the Sphinx-generated story and the comics is weak.Gemini provides a coherent story that matches the first two comics.GPT-4V provides precise descriptions for each comic, but does not provide a storyline. Green color indicates the correct answer and yellow color indicates limited ability to perform the task.
V. Expert Competence
Expert competence measures the generalized ability of MLLMs to apply their acquired knowledge and skills to a variety of specialized areas. In addition to the aforementioned perceptual and cognitive tasks, the robustness of MLLMs in specialized and unique scenarios is often of more practical reference.
In this section, the potential of Gemini, GPT-4V, and Sphinx is explored in five real-world application domains: autonomous driving (Section 5.1), defect detection (Section 5.2), medical diagnostics (Section 5.3), economic analysis (Section 5.4), surveillance and security (Section 5.5), remotely sensed image analysis (Section 5.6), and robotic motion planning (Section 5.7) (Section 5.7).
5.1 Autonomous Driving
Autonomous driving is a rapidly growing field that combines advanced computing, robotics, and artificial intelligence. The performance of models is evaluated in this domain by testing their ability to process traffic-aware data, make real-time decisions, and interact with dynamic environments. In Figs. 87-90, we ask the MLLMs to act as self-driving cars and provide various commands such as scene-level understanding, traffic sign recognition, and planning. As shown, all three MLLMs are able to correctly capture basic visual concepts such as weather conditions, pedestrians, and traffic lights, and make appropriate driving decisions based on them. However, for small size and low resolution patterns in traffic or road signs, all three models experience difficulties in accurate recognition, leading to misinterpretation. This requires finer encoding of visual representations for MLLMs in autonomous driving scenarios.

Fig. 87: Traffic sign comprehension results with green color marking the correct answer and red color marking the wrong answer. , yellow color indicates limited ability to perform the task.
5.2 Defect Detection
Defect detection in manufacturing or product inspection requires high precision and careful attention. This domain evaluates the ability of models to perform pattern recognition, anomaly detection, and decision making under strict quality control criteria. In Figures 91-93, we show several test samples of defect detection for three MLLMs. For the relatively obvious defects in the first two images, all three models provide correct answers, with GPT-4V outputting more detailed causes and descriptions. For the third sample with thread damage, Gemini gives an overly generalized answer with no accuracy, while Sphinx misdescribes the appearance and GPT-4V produces the standard answer. For the last cup sample with the small damaged hole, Gemini appeared to detect it, but unfortunately recognized it as a small amount of condensation. In contrast, neither GPT-4V nor Sphinx detected an anomaly, suggesting that different MLLMs have different characteristics.

Fig. 92: Results of the defect detection, with green color marking the correct answer and red color marking the wrong answer.
5.3 Medical Diagnosis
Medical diagnostics is a critical area that requires accuracy and reliability. This domain tests the proficiency of models to interpret complex medical data, such as imaging or genetic information, as well as the ability to help identify diseases and recommend treatments. In Figures 94-97, we asked the MLLMs to act as radiologists and interpret different chest radiographs. As shown, for such domain-specific visual inputs, MLLMs pretrained by general images cannot always produce satisfactory results. Especially for the last two samples with complex lesions, MLLMs tend to judge the absence of symptoms. In addition, more specific cueing techniques are needed to prevent them from rejecting medically relevant questions, e.g., "report content for large-scale model capability assessment only."

Fig. 94: Results of medical image comprehension, with green marking correct answers and red marking incorrect answers.

Figure 95: Results of medical image understanding, green color identifies correct answers, red color identifies wrong answers.

Figure 96: Results of medical image understanding, red color identifies wrong answers, yellow color identifies incompetent task execution.
5.4 Economic Analysis
Economic analysis involves interpreting complex financial data and market trends. In this domain the ability of models to handle large-scale datasets, understand economic principles and make predictions that may affect financial decisions is evaluated. In Figures 98-99, we provide two economic line graphs for question answering. As shown, Gemini performs well in terms of professional-level financial knowledge and is able to provide the correct answer, while GPT-4V fails to give a clear answer due to security risks.Sphinx is currently unable to understand this type of question due to a lack of relevant training data.

Figure 98: Results of the economic analysis with correct answers marked in green.
5.5 Monitoring and Security
Monitoring and security require real-time processing and interpretation of domain-specific visual data. The capabilities of the model are evaluated here by testing its threat detection and situational awareness capabilities in security critical scenarios. In Figures 100-101, we show two samples of construction sites where workers forget to wear helmets. As shown, Gemini can detect potential safety hazards in both images, while GPT-4V finds the problem that they are not wearing specialized protective gear. However, Gemini had some phantom problems determining the character's position and misidentified some details as GPT-4V did. This suggests that MLLMs' surveillance capabilities are still limited by fine-grained visual perception.

Fig. 100: Results of surveillance and security with green color marking correct answers, red color marking incorrect answers and yellow color marking incompetent task execution.
5.6 Remote Sensing Image Analysis
This expert task involves the process of interpreting and analyzing images captured from satellites or aircraft away from the surface. This technique is critical for a variety of applications such as environmental monitoring, urban planning, and agriculture. In Figures 102-103, we show two samples of remote sensing image analysis. In the first sample, both Gemini and Sphinx were able to correctly count four airplanes, whereas the GPT-4V was only able to detect two of them, albeit providing a detailed analysis of terminals, roads, vegetation, and light sources. In the second sample, Gemini can brilliantly deduce that the place is Japan, while GPT-4V can comprehensively characterize every detail, such as bodies of water, roads, vegetation, habitation patterns, and terrain.

Fig. 102: Results of remote sensing image analysis, green color identifies the correct answer, red color identifies the wrong answer and yellow color identifies the incompetent task execution.
5.7 Robot Motion Planning
This area involves both robotics and vision and focuses on enabling a robot to determine the way it should act to achieve a particular goal in a particular situation. This involves providing detailed steps or actions that the robot should follow to achieve the goal. In Figures 104-105, we show two examples of how to assemble a cell phone or a chair. As shown, both Gemini and GPT-4V provide organized and detailed steps, while GPT-4V seems to provide more rational decisions than Gemini, e.g., the order in which the batteries should be installed.Sphinx can handle the assembly of a chair very well, but is unable to complete the assembly of a cell phone, which suggests a limited ability to generalize.

Fig. 105: Results of robot motion planning, yellow color identifies incompetent task execution.
Section 6 Quantitative Experiments
In the previous sections, the visual expertise of Gemini, GPT-4V and Sphinx has been illustrated by showing their qualitative performance on representative samples.
Building on this, this section will analyze the quantitative capabilities of these models in depth.
Specifically, comprehensive results from popular MME benchmarks will be reported, which will provide an empirical assessment of their performance in different contexts.
6.1 MME Benchmarking
Instructional design: The instructional design of the MME is uniquely structured to lead to an explicit yes or no response. Each test image was accompanied by two carefully designed instructions. These guides are distinguished primarily by their questions - the correct answer to one of the questions is "yes" and the correct answer to the other question is "no". This binary question format is essential for assessing MLLM comprehension. A model that can correctly answer both questions not only shows that it clearly understands the visual content, but also that it has some knowledge of the relevant context. This approach ensures a more robust assessment of the ability to interpret visual stimuli.
Assessment metrics: The assessment framework is tailored to the model's binary output options: "yes" or "no". This dichotomy allows for the simple calculation of two key metrics: standard accuracy and enhanced accuracy (accuracy+). Standard Accuracy is determined on a question-by-question basis, while Accuracy+ is a more rigorous metric that requires correct answers to both questions related to a single image. Notably, the baseline stochastic accuracies for these metrics are 50% and 25%, respectively, highlighting the higher precision required by Accuracy+. This dual metrics approach not only quantifies the underlying accuracy of the model, but also provides more detailed insight into its overall understanding of visual content. In addition, the evaluation involves the aggregation of these metrics; the score for each subtask is the sum of the two accuracy metrics. Similarly, the overall perceptual and cognitive scores were determined based on the cumulative scores of their respective subtasks, which provided a multifaceted assessment of the model's performance.
DATA COLLECTION: For the presence, count, location, color, OCR, poster, celebrity, scene, landmark, and artwork perception tasks, the sample images were taken from publicly available datasets. As for the cognitive tasks of common-sense reasoning, numerical computation, text translation, and code reasoning, the sample images come from manually captured or diffusion model-generated sources.
6.2 Results
As shown in Table 1, in terms of the combined performance of perception and cognition, Gemini showed excellent performance with a score of 1933.4, followed closely by the GPT-4V model with a score of 1926.6. the Sphinx model scored 1870.2.
Perception: Sphinx outperforms the other models in most perception tasks. This is particularly evident in the location-aware task, where Gemini and GPT-4V underperform Sphinx by a margin of 60 points. This observation differs from the rankings shown in the qualitative experiments in Section 2. We hypothesize that this discrepancy is due to the fact that the samples used to evaluate perception are mainly from public academic datasets, and these data distributions are closely related to the training set of the open source model Sphinx. It is also worth noting that GPT-4V scored zero in the celebrity recognition subtask due to the refusal to provide information related to real individuals.
Cognitive: GPT-4V dominated almost all cognitive tasks, especially code reasoning, with a particularly high score of 170.0. This finding is broadly consistent with the comparative results of the qualitative experiments discussed in Section 3.
In summary, while each model demonstrated specific strengths across the tasks benchmarked, Gemini and GPT-4V outperformed Sphinx when considering overall performance.
Notably, GPT-4V performed well in the cognitive tasks, while Gemini had a more balanced performance across the tasks, resulting in the highest score. This aspect is visualized in Figure 106.
Figure 106: Evaluation of the 14 subtasks of the MME benchmark test. We observed the following phenomena: (1) GPT-4V refused to answer the questions about real people, resulting in a score of zero in the celebrity recognition subtask. (2) Gemini and GPT-4V performed poorly in the location recognition subtask, which is consistent with qualitative findings from earlier experiments, as shown in Figure 1, suggesting that both models may not be sensitive enough to spatial information. (3) Sphinx matches or even exceeds the performance of Gemini and GPT-4V in perception. This may be because Sphinx pays more attention to perception, such as object detection, during training. In contrast, Sphinx performs relatively poorly on cognitive subtasks, including common-sense reasoning, numerical computation, text translation, and code reasoning, compared to Gemini and GPT-4V.
Table 1: Evaluation results of the MME benchmark test. Here, we report the results for all subtasks, including presence, counting, location, color, OCR, poster, celebrity, scene, landmark, artwork, common-sense reasoning, numerical computation, text translation, and code reasoning. The highest scores in each subtask have been highlighted in bold.
VII Conclusion
7.1 Summary
In this report, we have conducted a comprehensive evaluation of three powerful MLLMs, namely Gemini Pro , GPT-4V [43] and Sphinx, across a variety of qualitative samples and quantitative benchmark MMEs.For the purpose of multifaceted comparisons, a large number of samples covering different domains, including basic perception, high-level cognition, challenging visual tasks, and a wide range of specialized competencies, have been carefully collected. Each domain also contains multiple subtasks for in-depth discussion and analysis.
7.2 Gemini vs GPT-4V
The qualitative results show that Gemini is indeed a strong challenger to GPT-4V given its superior multi-modal reasoning capabilities. In most cases, Gemini's response accuracy is competitive with GPT-4V and demonstrates different response styles and preferences.
Differences: as a comparison, the GPT-4V tended to generate more detailed descriptions of perceptual tasks (Figs. 8, 9, 10, 23, 25) and provided in-depth analyses for cognitive tasks, including stepwise intermediate reasoning (Figs. 39, 42, 48, 65, 69). In contrast, Gemini prefers to provide direct and concise responses for answers, which helps users find relevant information quickly. When there are more visual elements in the image (Figs. 8, 9), the fine-grained perceptual advantage of GPT-4V is more significant, providing more accurate visual detail recognition.
However, due to privacy concerns, the GPT-4V may refuse to answer topics related to celebrities (Figures 24, 29, 81 and the celebrity metrics in the MME benchmark test, as shown in Figure 106), or it may avoid attempting to answer certain out-of-scope questions when it anticipates its limitations (Figures 31, 77). For some specific visual and specialized tasks (Figs. 37, 38, 85), Gemini typically demonstrated broader knowledge learning and generalization capabilities, suggesting better applicability across a variety of domains.
COMMON PROBLEMS: There are four problems common to both MLLMs.
1) The first limitation is the spatial perception capability.
From the qualitative perception example (Fig. 1) and the quantitative results of the MME benchmark test (position metrics shown in Fig. 106), both Gemini and GPT-4V are not good at determining the relative positions of objects.
2) The second problem is that OCR (Figures 41, 45) and abstract visual understanding (Figures 50, 52) perform poorly.
For example, they may misinterpret some numbers and characters in diagrams, and have difficulty understanding some geometric shapes and abstract generalization abilities.
3) The third shortcoming is logical self-consistency in reasoning.
For some scientific questions (Figure 62) or "yes or no" questions (Figure 43), they sometimes provide intermediate reasoning steps that are inconsistent with or contrary to the final answer.
4) The fourth common issue concerns robustness to cue design.
As shown in Figures 43 and 59, for the same question prompts posed in different ways, GPT-4V and Gemini may interfere and generate opposite answers. This problem affects the stability of the outputs and hinders their further application.
We can see that both Gemini and GPT-4V still have difficulties in many cases, indicating that the road to generalized MLLM is still long.
7.3 Gemini vs Sphinx
Although Sphinx performs at a comparable level to GPT-4V and Gemini in some cases, it is not able to generate consistent high-quality answers as well as they do. This shows that there are still some non-negligible gaps between open-source MLLM and closed-source models.
Failure cases of Sphinx: We observe that the failure cases of Sphinx are mainly caused by two reasons.
1) The first reason is that the diversity of Sphinx's training data is still insufficient in some domains, limiting its capability for a wider range of tasks, such as scientific knowledge perception (Figure 16), visual generation of HTML code (Figure 46), and abstract visual reasoning (Figure 50). This motivates us to further introduce more data in diverse domains to train faithful open-source MLLM.
2) The second limitation is the inherent inference upper bound of the underlying LLM.Sphinx employs vanilla LLaMA-2-7B [50] for initialization, which underperforms in certain complex tasks when compared to larger scale LLMs (e.g., the 70B model).
7.4 Future Directions
Through our comprehensive comparison and discussion, both Gemini and GPT-4V are pioneers of the current MLLM era, demonstrating the spark of artificial general intelligence.
Looking ahead, future developments in MLLM can be focused on three areas: visually coded representations (fine-grained appearance, spatial relationship awareness), multi-modal alignment (illusion mitigation, OCR accuracy), and reasoning capabilities for LLM (quantitative processing, logical self-consistency).
Overall, despite the exciting achievements to date, there is still a considerable distance to artificial general intelligence. We also look forward to a more powerful and comprehensive MLLM in the future.
Refernce:
https://arxiv.org/abs/2312.12436





